
결정 트리
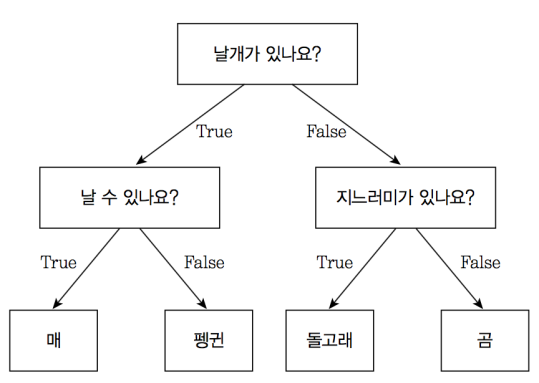
Decision Tree는 특정 질문에 따라 데이터를 구분하는 모델입니다. 분기마다 항상 변수 영역을 두 개로 구분하는 Binary Tree의 형태를 가집니다. 트리의 기본 구조에 따라 첫 노드(=첫 질문)은 Root Node, 마지막 질문(=마지막 노드)는 Terminal Node(Leaf Node)라고 합니다.
깊이가 깊어질수록 의사 결정에 따른 데이터가 나뉘게 됩니다.


다만 지나치게 깊은 의사결정트리로 데이터를 구분하게 되거나 결정 트리에 아무 Parameter도 주지 않고 모델링을 할 경우 오버피팅이 발생합니다.
- Pruning(가지치기): 오버피팅 상황을 방지하기 위한 기법입니다. Network에 각종 Constraint를 주고 모델링을 진행합니다.
- 종류: 최대 깊이, 최대 터미널 노드 수, 노드 분할 시 최소 데이터의 수 등
- 분류: 사전 가지치기, 사후 가지치기
- Entropy(엔트로피): 불순도를 수치로 나타낸 척도입니다. 엔트로피와 불순도는 비례합니다. 0부터 1까지의 값을 가집니다.
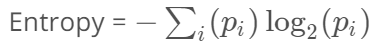
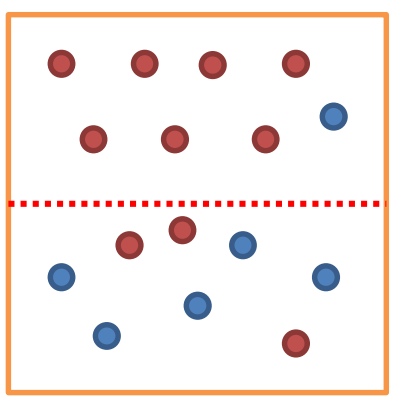
- Impurity(불순도): 분류된 하나의 범주 안에 다른 데이터가 섞여 있는 정도를 말합니다. 아래 이미지와 같은 경우 파란 점이 섞여있는 정도가 낮은 위쪽 범주의 불순도가 더 낮습니다.
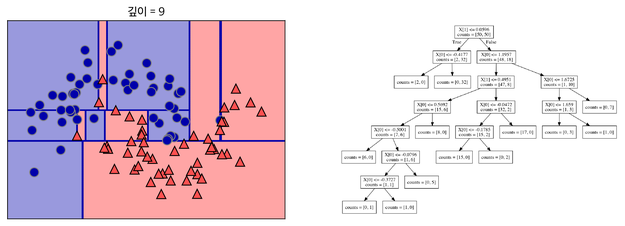
랜덤 포레스트
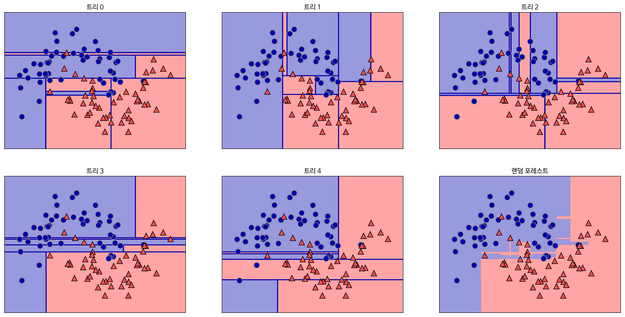
결정 트리를 만들 때, 많은 Feature를 이용하게 되면 그만큼 가지가 많아지고 이는 오버피팅이 발생하는 원인이 됩니다. 이 Feature 중 랜덤으로 n개만 선택해서 결정 트리를 만드는 과정을 m번 반복하여, m개의 결정 트리를 만들 수 있습니다(예를 들어, 30가지의 Feature 중 랜덤으로 5가지를 뽑아서 결정트리를 만드는 과정을 5번 반복할 수 있습니다). 이러한 여러 개의 결정 트리들의 예측값들 중 가장 많이 나온 값 하나를 최종적으로 선택합니다. 이러한 결과 선택 과정을 앙상블(Ensemble)이라고 합니다. (블로그에서 가장 와닿었던 대목은, “문제를 풀 때 한명의 똑똑한 사람보다 100명의 평범한 사람들이 더 잘 푼다”라는 부분이었습니다.)
위 사진에서 아래쪽 최우측에 있는 그림이 랜덤 포레스트의 Decision Boundary입니다. 나머지는 총 5개의 결정 트리 각각의 Decision Boundary를 보여줍니다.