
- 원문: https://arxiv.org/abs/1805.10180
- 참고자료: 논문요약
- 대분야: Image Segmentation
- 소분야: Semantic Segmentation, Network Hierarchy
- 키워드: PAN (Pyramid Attention Network), GAU (Global Attention Upsample)
문제점

[1] 공간해상도 손실 (Spatial resolution loss)
작은 객체 부분 Segmentation 정확도가 낮습니다. 다중 스케일 상에서 객체들의 카테고리를 결정하는데 문제가 있어 SPP나 ASPP를 사용하게 됩니다.
![Part Ⅶ. Semantic Segmentation] 6. DeepLab [1] - 라온피플 머신러닝 아카데미 - : 네이버 블로그](https://mblogthumb-phinf.pstatic.net/MjAxNzA1MDhfMTgg/MDAxNDk0MjA0NzM4MDA5._TkcVvaXD5-r-jyXciSTN-hKi1dga-Id3sNLDH3qpXIg.irXD5TPtE9L3UTi2jjgkgm9s6fkjx9xtbmCpiFSfg48g.PNG.laonple/%EC%9D%B4%EB%AF%B8%EC%A7%80_105.png?type=w2)
다만 이렇게 하면, 그리드 모양의 Artifact를 만들어 버린다는 단점이 있습니다. 논문에서는 이러한 단점을 보완하여 CNN의 출력으로부터 High-level feature의 Pixel-level attention을 추출하는 FPA(Feature Pyramid Attention)을 제안합니다.
[2] Segmentation Detail 손실 (Weak in restructuring original resolution binary prediction)
최상단의 그림에서 볼 수 있듯이, FCN의 경우 Segmetnation의 결과가 sharp하지 않습니다. 자전거의 핸들은 아예 없어져 있습니다. 이러한 문제는 U-Net 구조를 이용하거나 Kernel을 크게 접으면 어느정도 해결된다고 알려져 있습니다(논문 참조). 다만 연산량이 많아지는 문제가 있습니다. 이러한 문제를 논문에서는 GAU(Global Attention Upsample)모듈을 제안하고 이 모듈에서 global context를 추출하였습니다. 다른 방식들보다 연산량이 적다고 합니다. VOC2012 Cityscapes에서 SOTA를 달성했다고 합니다.
제안요소
Feature Pyramid Attention (FPA) Module
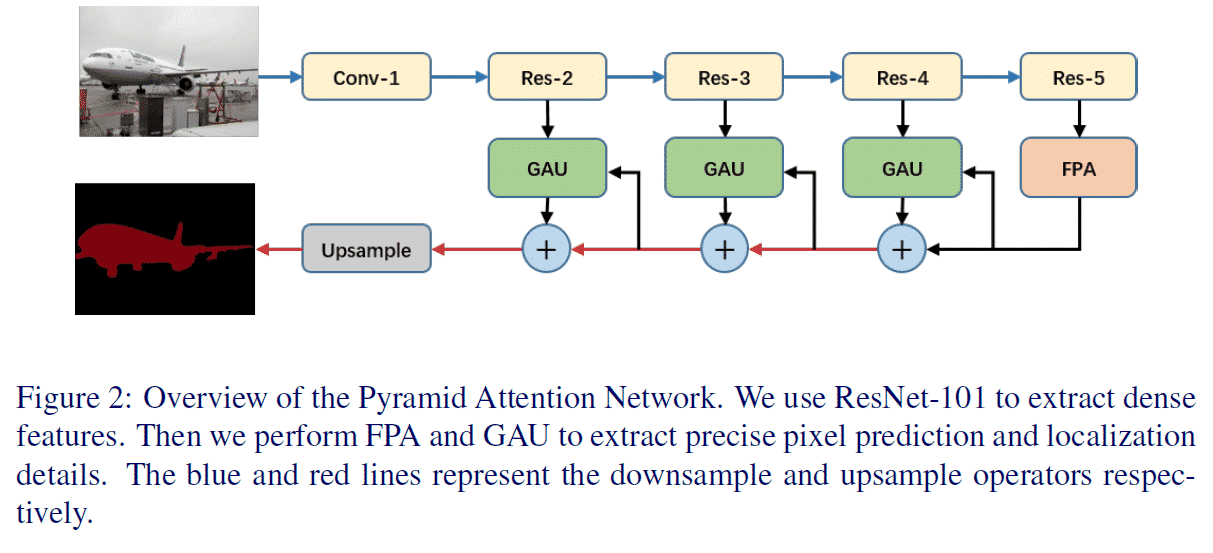
네트워크는 인코더-디코더 아키텍쳐로 구성되어 있습니다. Res-5까지 거쳐서 인코딩된 결과가 Feature Pyramid를 통과해 Attention을 받아(?), 원본 크기로 다시 커지게 됩니다. 파란색 선이 Downsampling, 빨간색 선이 Upsampling입니다.
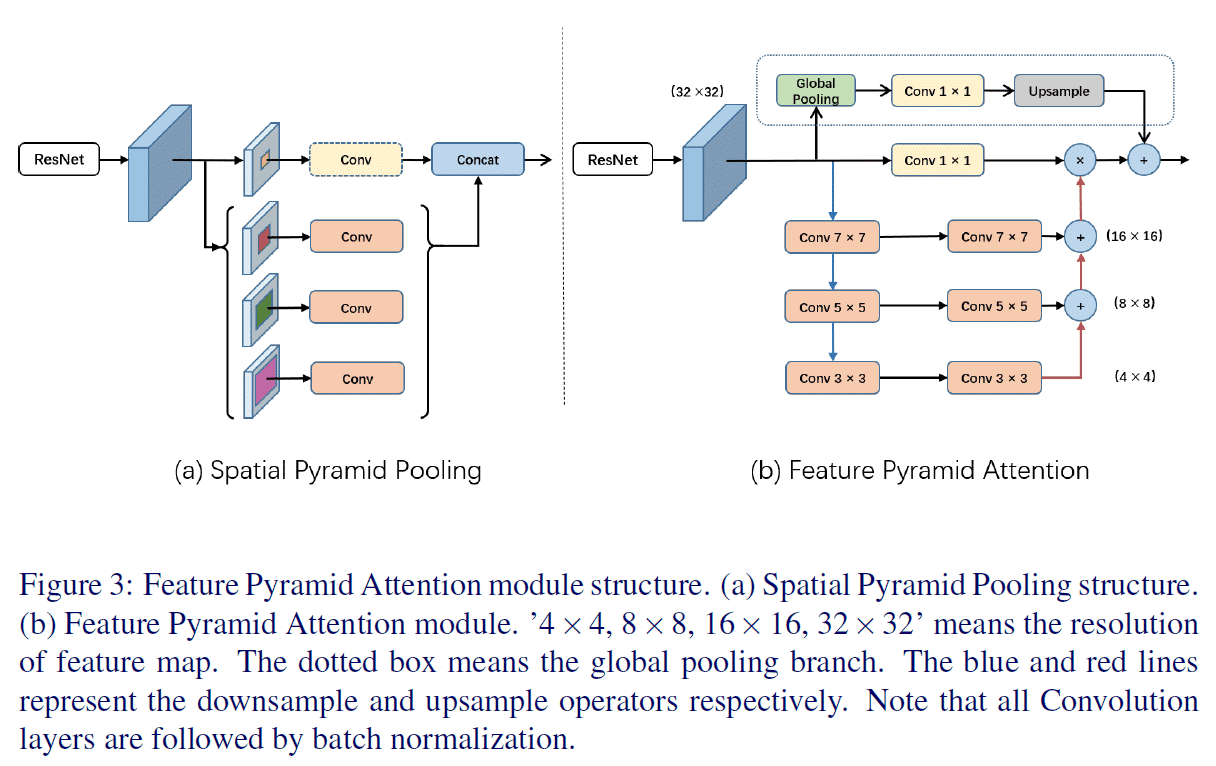
- 참고: Spatial Pyramid Pooling
- 특징
- Feature Pyramid Network와 비슷한 구성
- 3개의 스케일을 이용하여 U-Shape structure 구성
- Feature 자체가 작아서, 커널 크기를 크게 해도 (e.g. 7×7) 계산량이 매우 커지지는 않음
Global Attention Upsample (GAU) Module
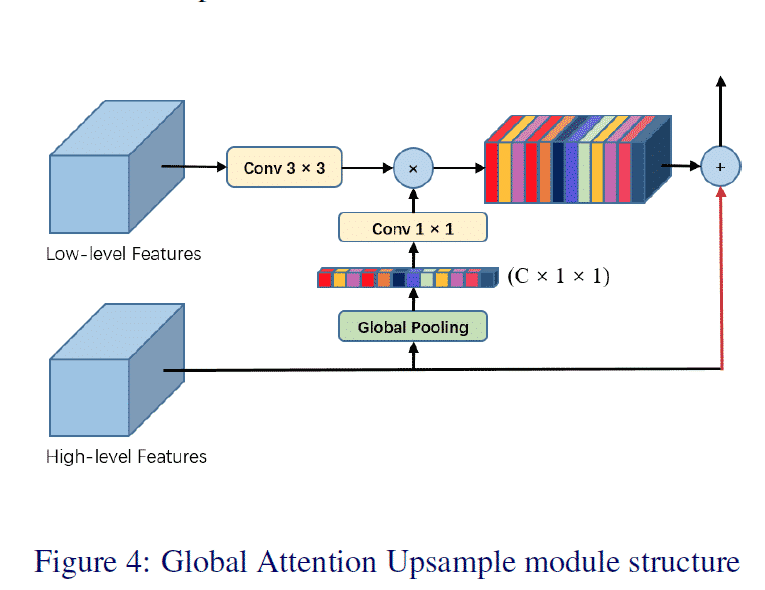
Decoder단에서의 성능을 끌어올리기 위해 PSPNet이나 DeepLab에 사용된 Bilinear 방식과, DUC에서 사용된 One-step decoder module에서의 문제점을 지적하였습니다. GAU에서는 Decoder에서의 Upsampling 시, Low-level feature과 High-level feature를 동시에 볼 수 있는 방식을 고안하였습니다. (마찬가지로, 빨간색이 Upsampling입니다.)
성능
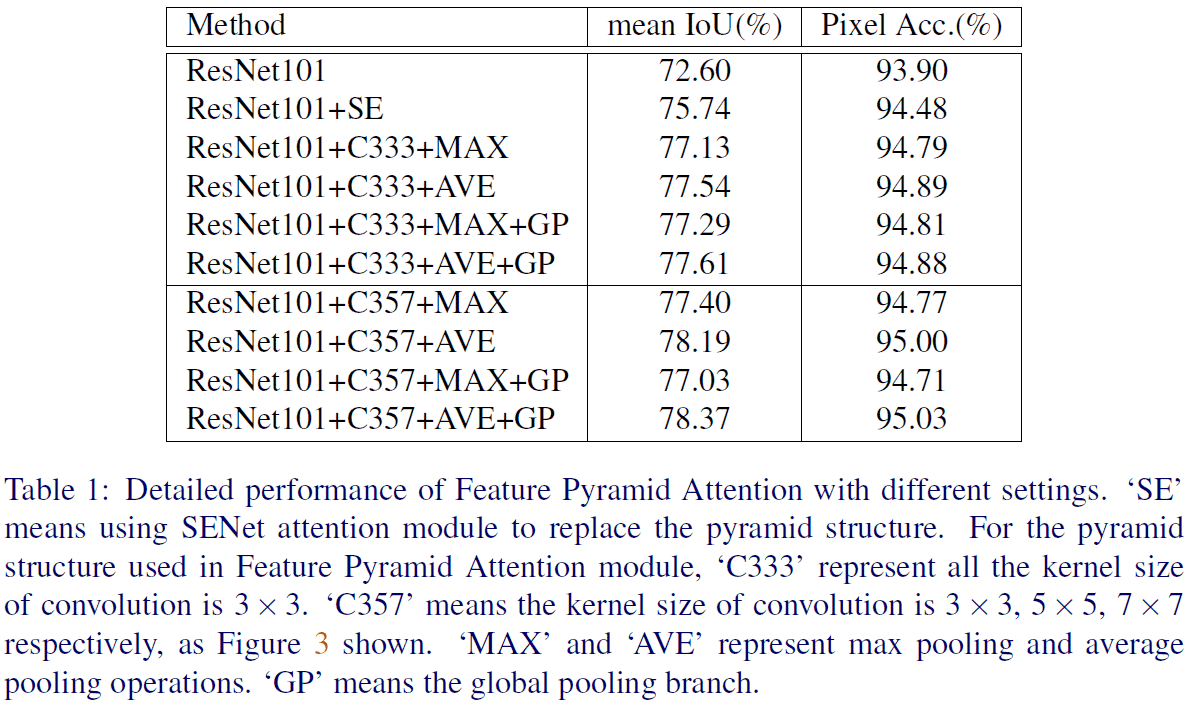
SE는 SENet Attention Module을, C333/C357은 각각 커널 사이즈 3-3-3과 3-5-7의 Feature Pyramid Attention Module의 사용을 나타냅니다. MAX와 AVE는 각각 Max Pooling, Average Pooling을 나타내며 GP는 Global Pooling Branch (FPA 상단)를 나타냅니다.
“[베이스리뷰 2주차] 간단정리 – Pyramid Attention Network”에 대한 한개의 댓글